Kernel-Based Dynamic Ensemble for Imbalanced Data Classification with Overlapping Classes
A new research paper introduces a kernel-based dynamic ensemble approach designed to effectively classify imbalanced datasets that feature overlapping classes. This method aims to improve the accuracy and robustness of machine learning models when dealing with complex, real-world data distributions. The study addresses a significant challenge in data science where traditional classifiers often struggle.
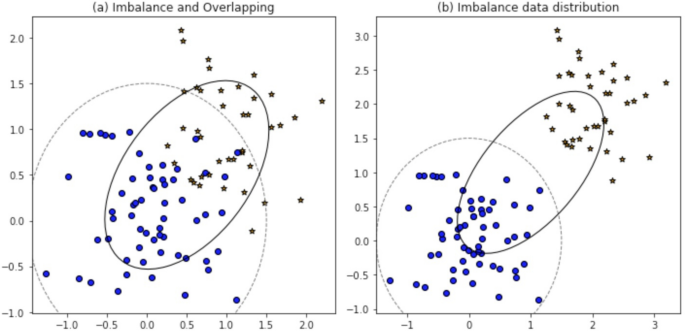
The paper, published in Scientific Reports, details an innovative kernel-based dynamic ensemble approach. This method is specifically engineered to tackle the persistent problem of classifying imbalanced datasets, a common issue in various fields such as medical diagnosis, fraud detection, and anomaly detection. Imbalanced data, where one class significantly outnumbers others, often leads to biased models that perform poorly on minority classes.
Furthermore, the approach is designed to handle overlapping classes, a scenario where data points from different classes are not clearly separable, making accurate classification even more challenging. By employing a dynamic ensemble, the model can adapt its classification strategy based on the characteristics of the data, thereby enhancing its ability to distinguish between closely related classes.
The use of kernel functions allows the model to map data into higher-dimensional spaces, potentially making linearly inseparable data separable and improving the overall classification performance. This technique builds upon existing ensemble methods, adding a layer of sophistication to address the dual challenges of imbalance and overlap simultaneously.
This research holds significant implications for the development of more reliable and accurate machine learning systems, particularly in applications where misclassification of minority classes can have severe consequences. It offers a promising direction for improving the performance of AI and machine learning algorithms in complex, real-world data environments.